The illusion of integration

Introduction - illusion of integration
Integrations with third-party systems are very common these days, especially in healthcare, where teams integrate with EHRs, audit tools, background check solutions, clearinghouses, and many other systems. With the rise of AI solutions, I expect a larger wave of integrations with smaller third-party systems.
Some of these integrations are complex and require specialized data protocols. Others are just a set of REST API endpoints. Regardless of the data format, integration is often treated as simply sending data to another system and receiving data back.
On paper, that sounds very simple. Imagine the business comes to the technical team and asks them to integrate an existing system with a new partner system. You review the integration documentation and see that there is only one endpoint for sending data, and the partner system will report processing results to a specified webhook URL. Then the time comes for estimation: how long will it take to integrate, especially with the AI code-generation tools available today? One day?

In one day, you may get data flowing between systems. Many teams treat that moment as the finish line. In reality, it is only the beginning. Connectivity is the first milestone, not the definition of a successful integration. This is an illusion of integration.
Why quick integration isn't enough
At this stage, data is already flowing, and the team has probably conducted a happy-path demo. But that is not proof that the new workflow is reliable, observable, or safe for the business.
One of the most dangerous promises I have heard from a partner's system was: "Our system never fails." Of course, it did fail. And that is exactly the point. In real-world integrations, failure is never hypothetical. Systems become unavailable, data centers blow up, processing gets stuck, payloads evolve, and processing can break in ways that are invisible at first.
That is why a production-ready integration cannot be treated as a purely technical problem. Before calling it done, engineering and business should review failure scenarios together.
The technical team should ask questions like these:
- What happens if the partner system is unavailable?
- What happens if it accepts the request but cannot process it?
- What happens if it never reports the processing result?
- What happens if it reports the result in an unexpected format?
- What happens if it sends the same result twice?
The business team should be asked:
- How long can this workflow be delayed before it becomes a real problem?
- Who needs visibility into stuck processes?
- Is there a manual fallback for critical cases?
- Who owns recovery if the workflow breaks?
- How do we estimate the impact on operations, revenue, or compliance?
These questions may sound boring, but they are the real starting point of integration design.
A common response to failure scenarios is: "We'll log it". And that is not enough. Logs are useful for diagnosis, but they are not an operating model. If every issue requires engineers to inspect logs manually, the integration will not scale. Over time, that becomes a bottleneck and limits how many integrations the team can support safely.
A production-ready integration needs more than connectivity. It needs resilience mechanisms such as retries, idempotency, timeout handling, duplicate protection, and alerting. It also needs operational visibility so the right people can see when a workflow is stuck and respond before the business discovers it the hard way.
Each class of problem should have clear ownership. Some issues are solved in code. Others require an operational process. For example, if an integration is part of revenue cycle management and claim submission cannot be delayed, the business team needs visibility into stuck cases so they can intervene manually when necessary.
A simple test is this: if the team can answer "yes" to the following questions, the integration is probably in good shape:
- Can we confidently tell whether it is working today?
- Can we detect when it breaks?
- Can we estimate the impact?
- Can we recover missed transactions?
If the answer is no, then the integration may be connected, but it is not yet trustworthy.
What "done" should mean
Sometimes, in agile teams, it can be complicated to explain to the business why they already see the data flowing between systems, but the technical team still needs a few more sprints to work on it.
This is where the technical team should push back and explain that data flow is only the starting point from the operational standpoint. It requires time to build a system around the integration to call it trustworthy. In practice, it means that the system should be visible, measurable, recoverable, and owned.
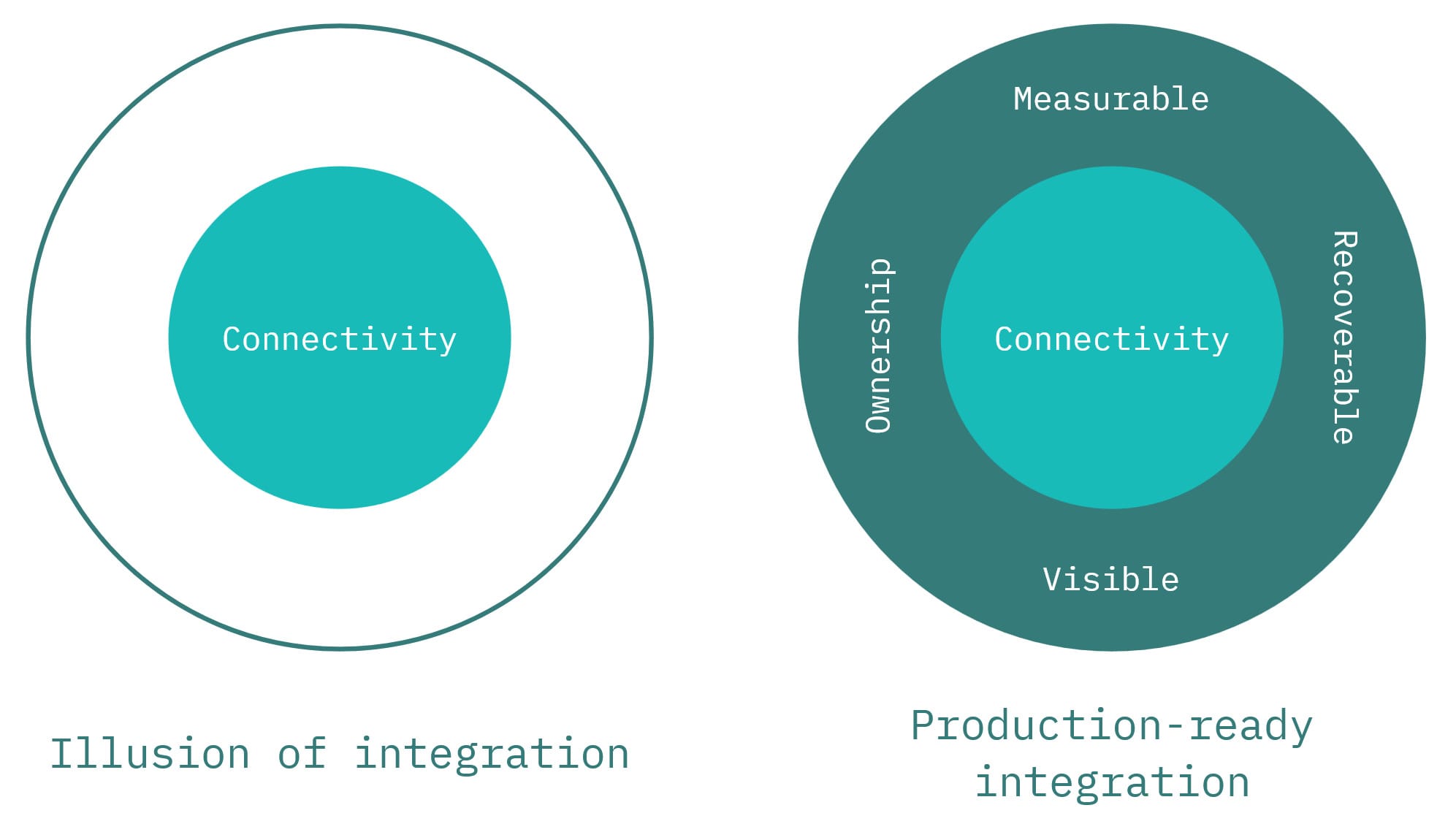
Visible means the team can see what is happening without manually digging through logs every time something goes wrong. If a request gets stuck, delayed, duplicated, or lost, the right people should be able to notice it quickly. Visibility may come from dashboards, alerts, workflow states, or support views, but the important part is simple: problems should not stay hidden until a business user reports them.
Measurable means the team can evaluate whether the integration is healthy. It is not enough to say that it "usually works". A production integration should have signals that help answer practical questions: how many requests succeeded, how many failed, how long processing takes, how many workflows are stuck, and whether the behavior is getting better or worse over time. If there is no way to measure health, there is no way to manage it.
Recoverable means failure does not automatically become data loss or business loss. Mature integrations are designed with the assumption that something will eventually break: a partner system may be unavailable, a callback may never arrive, or a payload may be processed incorrectly. When that happens, the team should have a way to retry, replay, reprocess, or fall back to a manual workflow. Recovery does not have to be perfect, but it has to exist.
Ownership means every important class of problem has a clear responsibility. Someone has to own technical failures, someone has to own operational response, and someone has to understand the business impact. Integrations often fail in the space between teams, where engineering assumes support will handle it, support assumes the partner will fix it, and the business assumes the workflow is still running. Clear ownership closes that gap.
This is why "data is flowing" is too weak to be a definition of done. It proves only that connectivity exists. It does not prove that the workflow is observable, supportable, or safe to depend on.
Conclusion
The difficult part is not building the first connection. It is aligning expectations around everything that must come after it.
Teams should communicate early that a production-ready integration needs more than a working endpoint. It needs time for visibility, recovery, and ownership to be built around the workflow.
In the next article, I will focus on what makes an integration trustworthy in production.