How a random seed secured our release

Before I dive into the story, let me briefly revisit the idea of a random seed. We all know that computers don't generate truly random numbers. Under the hood, every "random" value is produced by a deterministic function that accepts a seed. If you call that function with the same seed on different machines, you'll get the same sequence of outputs.
You probably remember this from university, but many engineers never use it again, depending on their specific domain. In gamedev, deterministic randomness is everywhere because it helps build reproducible multiplayer simulations. In healthcare, where I work, randomness is almost never part of the daily toolkit.
And that's exactly why the seed became a valuable tool in an unexpected situation.
The problem
We have two systems:
- External system that performs checks and enriches incoming data
- Internal system that consumes these enriched results and applies business logic
The external system had no testing environment. The only way to test anything was by sending data to a production environment. Not ideal, but at the time we had no alternatives.
The check output, which is performed by the external system, is simple: Passed/Not Passed. To extend our test coverage without affecting production, we began considering the creation of a mock service that mimics the behavior of the external system.
But building a full replica was too expensive: too many moving parts, tight deadlines, introducing new infrastructure entries, and risk of spending too many hours on it.
So, the challenge became: how do we simulate stable check results without storing anything in the mock service? We intentionally avoided persistence to keep the mock lightweight and isolated.
The solution
Switching from push to pull
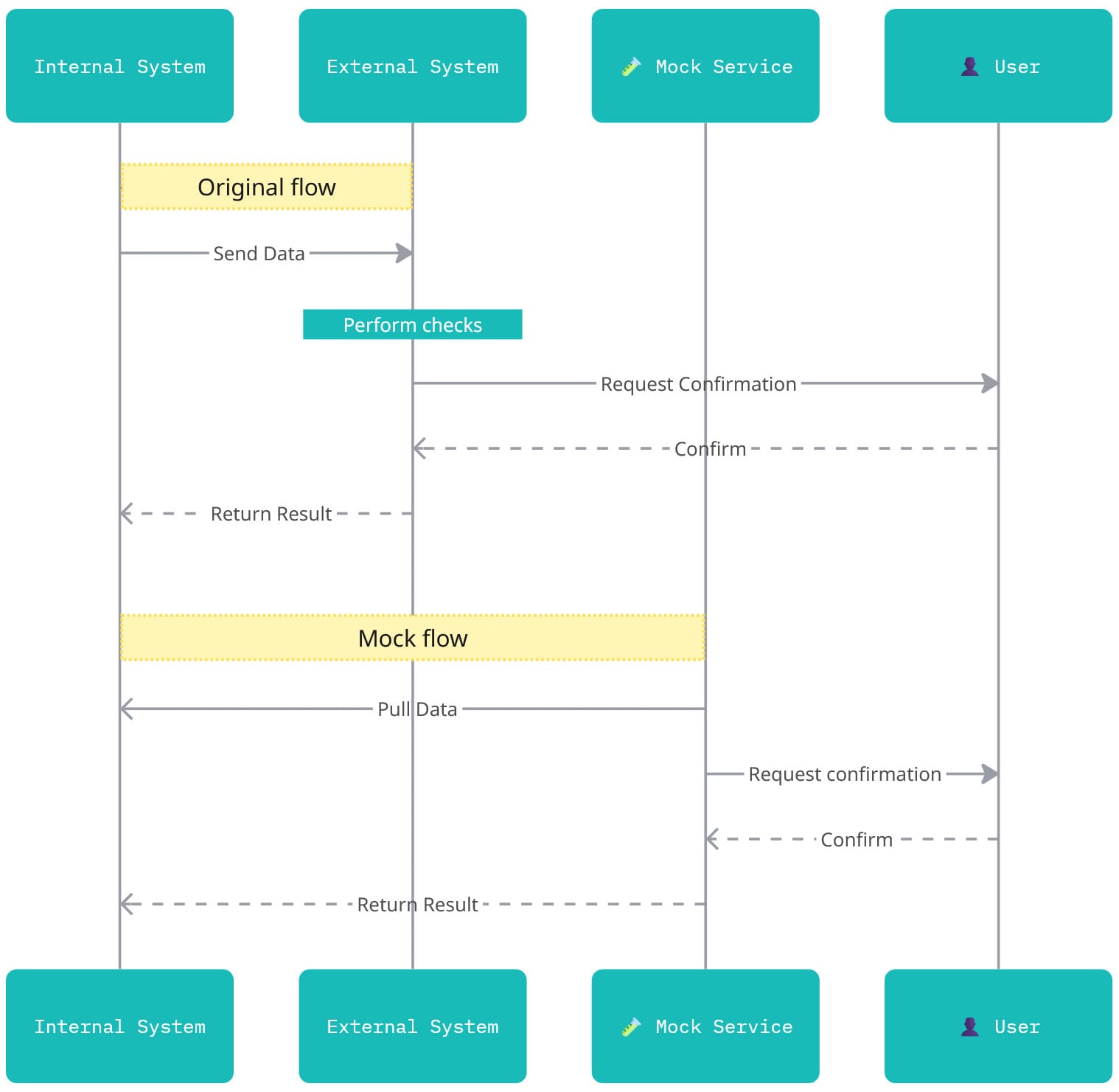
The external system expected our internal system to push data into it, and then it would push the results back. In the mock version, we changed only the first part of this flow. Instead of the internal system pushing data out, the mock service now pulls the records that are waiting for an external check directly from our existing API. The response flow remains the same: the mock still pushes the results back to the internal system, just like the external system would.
This approach enables us to avoid introducing new endpoints, infrastructure, or additional integration flows.
Consistent results
Once I generated a draft UI for the mock service, it became clear that each record needed a "check result" visible on screen. These results must be:
- consistent for every user
- consistent across different application restarts
- consistent across deployments
- generated without any database or additional storage.
This is where the seed stepped in.
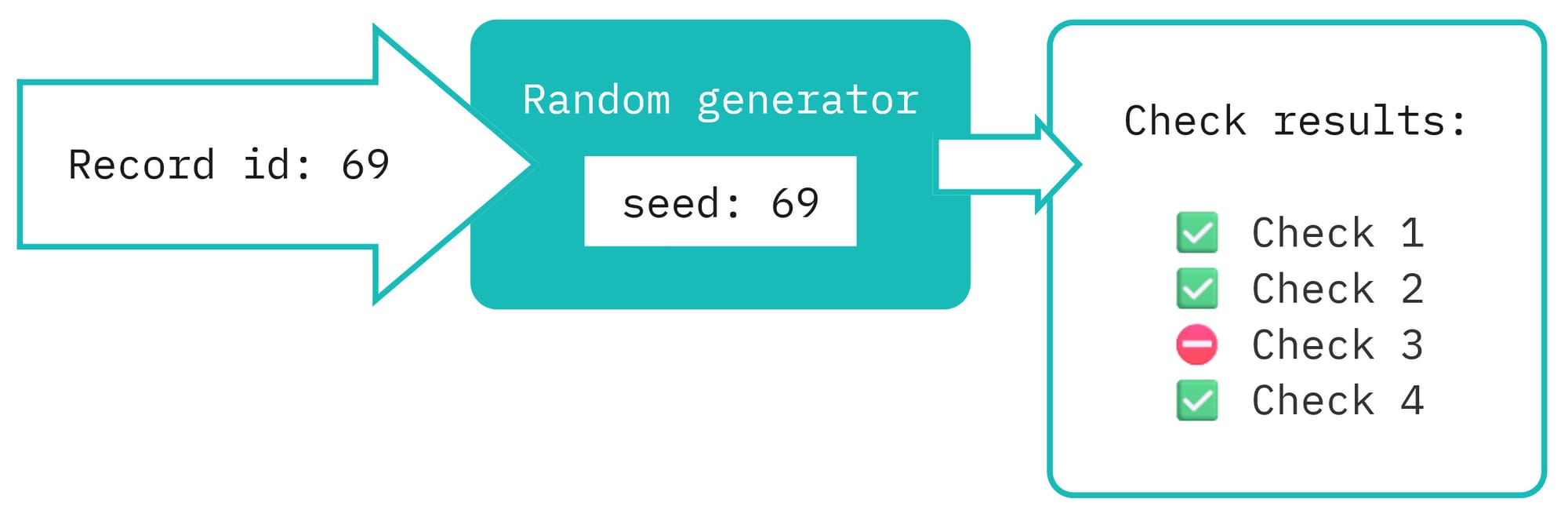
For each record, I initialize a new instance of a random generator using the record's unique ID as a seed. Then I generate the check results. It provides me with deterministic randomness (the same record ID always produces the same outcome), statelessness (no need to store any information), and simplicity.
You can extend this idea to generate entire sets of synthetic data: patient demographics, timestamps, flags, whatever you need. Everything stays reproducible and stable without any persistence layer.
It's a simple trick, but in this project, it saved us a significant amount of time, secured a planned release date, and prevented the need for new infrastructure (except for the service itself).