From missed dependencies to automated insights
Our team reviews hundreds of work items every release to understand their dependencies. We work in a distributed system, where each service has its own repository. This means that even an average medium-sized feature can affect a few services.
Sometimes, another team may contribute to your feature, making the picture even more complex. It quickly becomes difficult to answer a simple question: what services do we need to release when we are releasing the feature?
We have a pull request policy requiring engineers to link related work items. That's our primary way of tracking which services are impacted. But as I mentioned, with hundreds of work items in a release, manually reviewing each one to understand dependencies becomes tedious and time-consuming.
As a result, we were spending extra time manually chasing down dependencies, and worse, we still missed things. We ended up resolving the post-release incident when we realized a service hadn't been promoted due to a missed dependency.
The idea to solve this issue was born during the postmortem discussion of the incident. We were asking ourselves: what if we didn't have to do this dependency tracking manually? Imagine being able to generate an automated report with just one click.
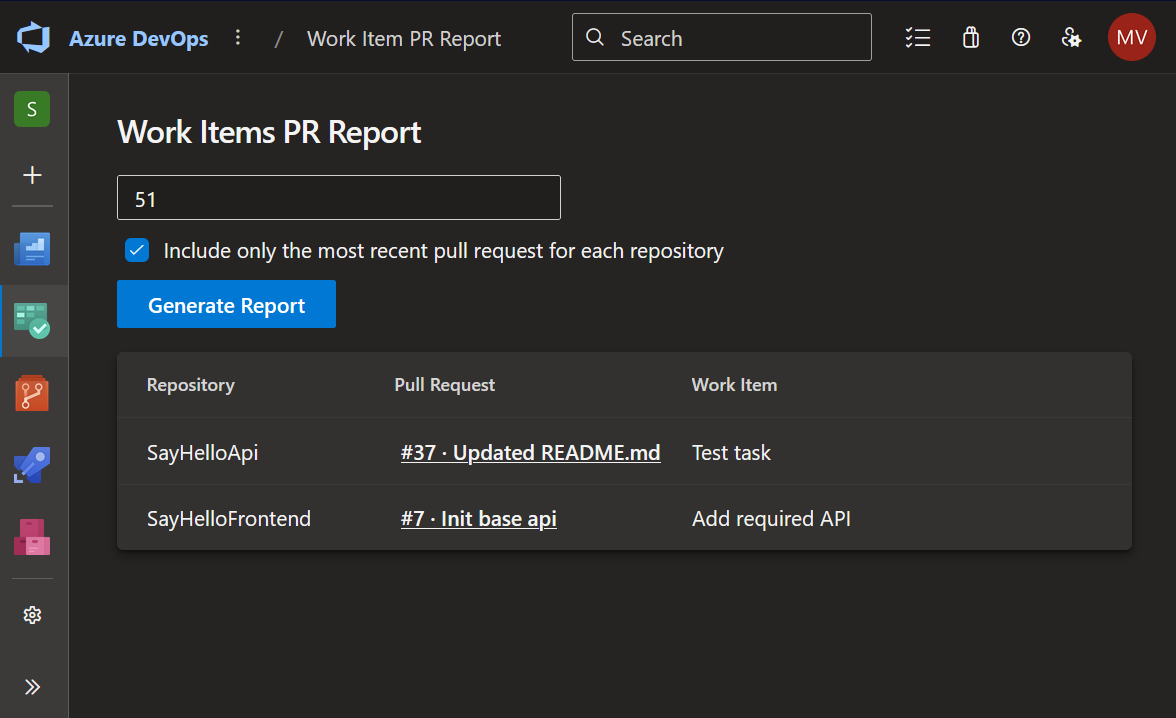
Technically, the concept sounded simple: traverse the work item hierarchy, find all links to pull requests, and include those pull requests in a report. Easy and obvious, right?
During the meeting, somebody said, "There is probably already something in the Azure DevOps for this". But when I checked, I was surprised to find nothing that actually fit our needs.
It was one of those ideas that keeps you awake at night. I decided to ride this wave of inspiration and build a proof of concept.
Implementation
This part of the post dives into implementation details. Feel free to skip ahead if you are just curious about the final integration.
I wanted to build it as a natural part of Azure DevOps because developers aren't the only ones who need to understand dependencies. I wanted technical managers and release managers to benefit, too. That's why I chose to make it an ADO extension, something installable from the marketplace, providing valuable insights in just a few clicks.
If you are interested in developing ADO extensions, I recommend starting with Microsoft's official guide. It explains the basics very well. If you have at least minimal frontend experience, it shouldn't be overwhelming, the tech stack is React and TypeScript.
Honestly, with tools like ChatGPT doing an amazing job with JavaScript code, it's a great helper for bootstrapping progress.
Also, I decided not to use any backend to keep the extension safe, especially for enterprise users. The extension should work only on the client side, making requests to Azure DevOps on behalf of the user. Nobody needs to host and maintain the backend, so there are no maintenance costs, and I can share it with the community.
The downside of the fully client-side application was that all requests to the SDK are executed on behalf of the user who uses the application. It means the user should have access to the repositories, because the extension uses a pull request SDK to get the name of the related repository.
Microsoft provides a great SDK with a library of ready-to-use components that cover most common scenarios. With this SDK, you don't need to overthink a UI design, you can stay focused on the actual application logic.
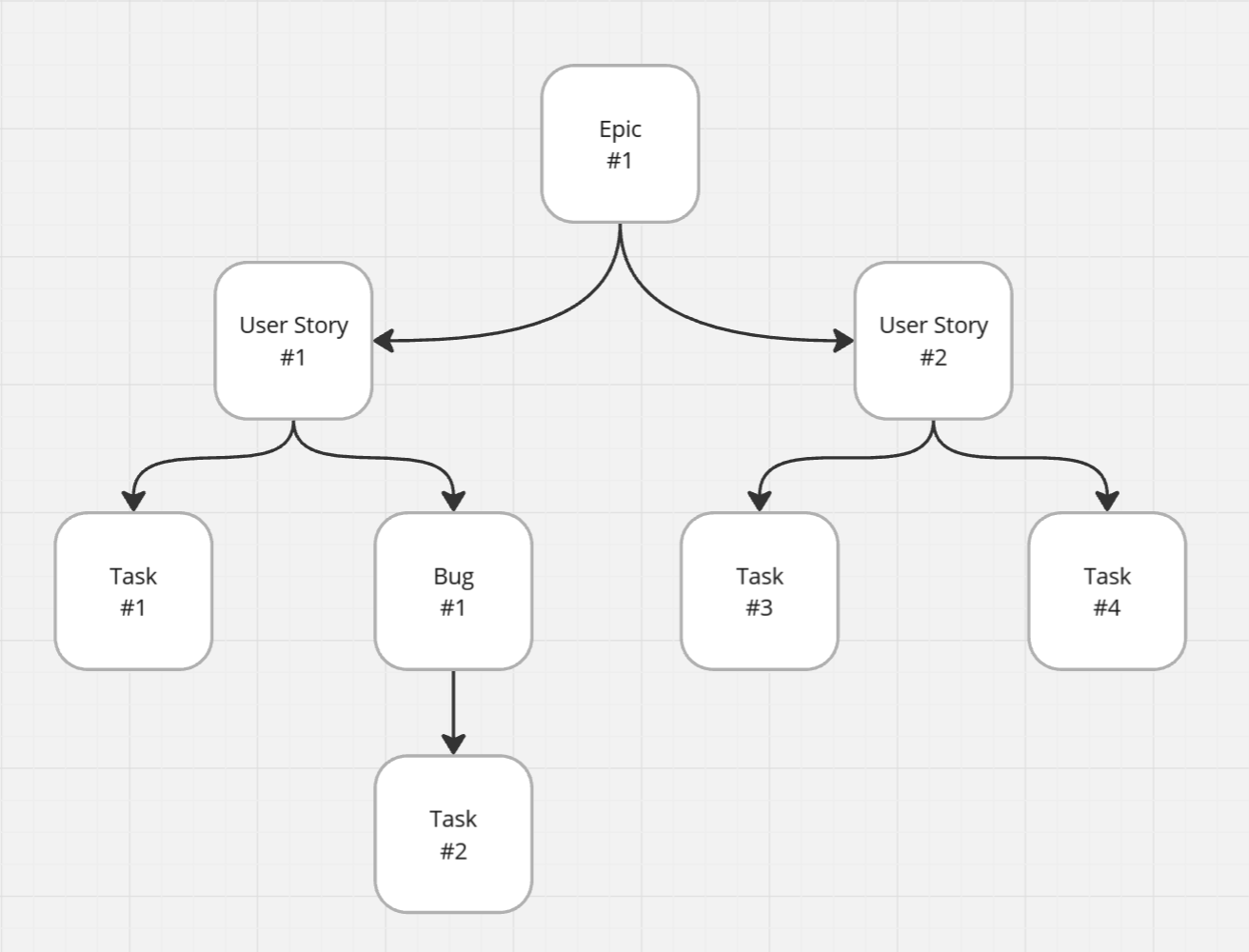
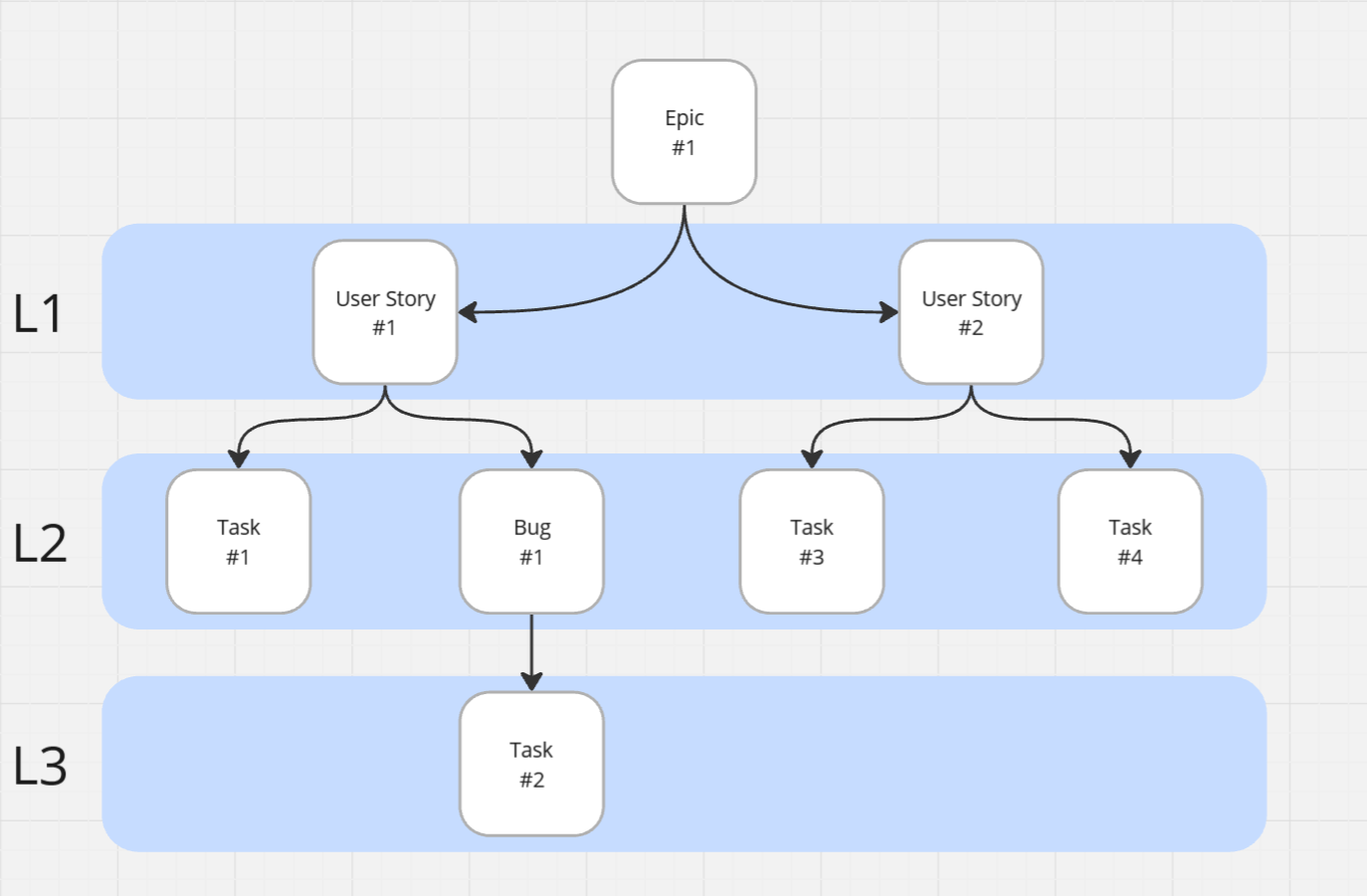
My initial implementation traversed the work item tree item by item. It worked... until we tested it on a real case: a work item with nearly 150 child work items underneath, with a few layers of depth. Scanning the entire hierarchy took several minutes.
Sure, it was still faster than manual checking, but I wasn't happy with the performance. I started looking for ways to optimize traversal. Thankfully, I quickly found a solution: the SDK has a powerful method for retrieving work items in batches.
I switched my approach to pulling each "level" of the tree in batches. The improvement was dramatic, in that same case, the extension became 10x faster.
Outcome
I received a lot of positive feedback about the extension from our team, and other teams started using it shortly after (of course, nobody enjoys tedious manual work).
But after the end of the day, why do you need to introduce tools like this to improve your release process?
- It saves time for your team and lowers the operating costs of releasing software. Let's say you release every two weeks, and an average release includes 700 work items. It it takes about 30 seconds to check the dependencies for each work item, that's around 6 hours per release, or 168 hours per year.
- You avoid spending engineers' time investigating and resolving incidents caused by missing dependencies. Production incidents aren't cheap, they can require emergency fixes, data recovery, customer support and follow-ups.
- You reduce the opportunity costs. How many customers abandoned their registration process because something wasn't deployed? How many of them didn't make the payment? What is the downstream impact on your partners? How does it affect your long-term relationship? It's hard to calculate these indirect costs, and of course it depends on your business model. But I can confidently say that the number isn't zero.
- You don't need to spend your own resources building this tool from scratch. You can just try mine. It's safe, runs entirely on the client side, and (finally!) it's completely free.
If you work with distributed systems and haven't yet encountered the pain of managing dependencies during releases or have a "not-so-funny" story about a missing dependency, please leave a comment. I'd love to discuss it!